Ministral 3
Ministral 3
Ministral 3 series, available in three model sizes: 3B, 8B, and 14B parameters. Provides best of class cost-to-performance ratio.
Memory Requirements
To run the smallest Ministral 3, you need at least 2 GB of RAM. The largest one may require up to 10 GB.
Capabilities
Ministral 3 models support tool use, vision input, and reasoning. They are available in gguf.
About Ministral 3
The Ministral 3 series is a family of open-weights models from MistralAI. These models were trained alongside Mistral's larger Mistral-Large model, and they are available in three model sizes: 3B, 8B, and 14B parameters. These models support image understanding and multilingual capabilities, available under the Apache 2.0 license.
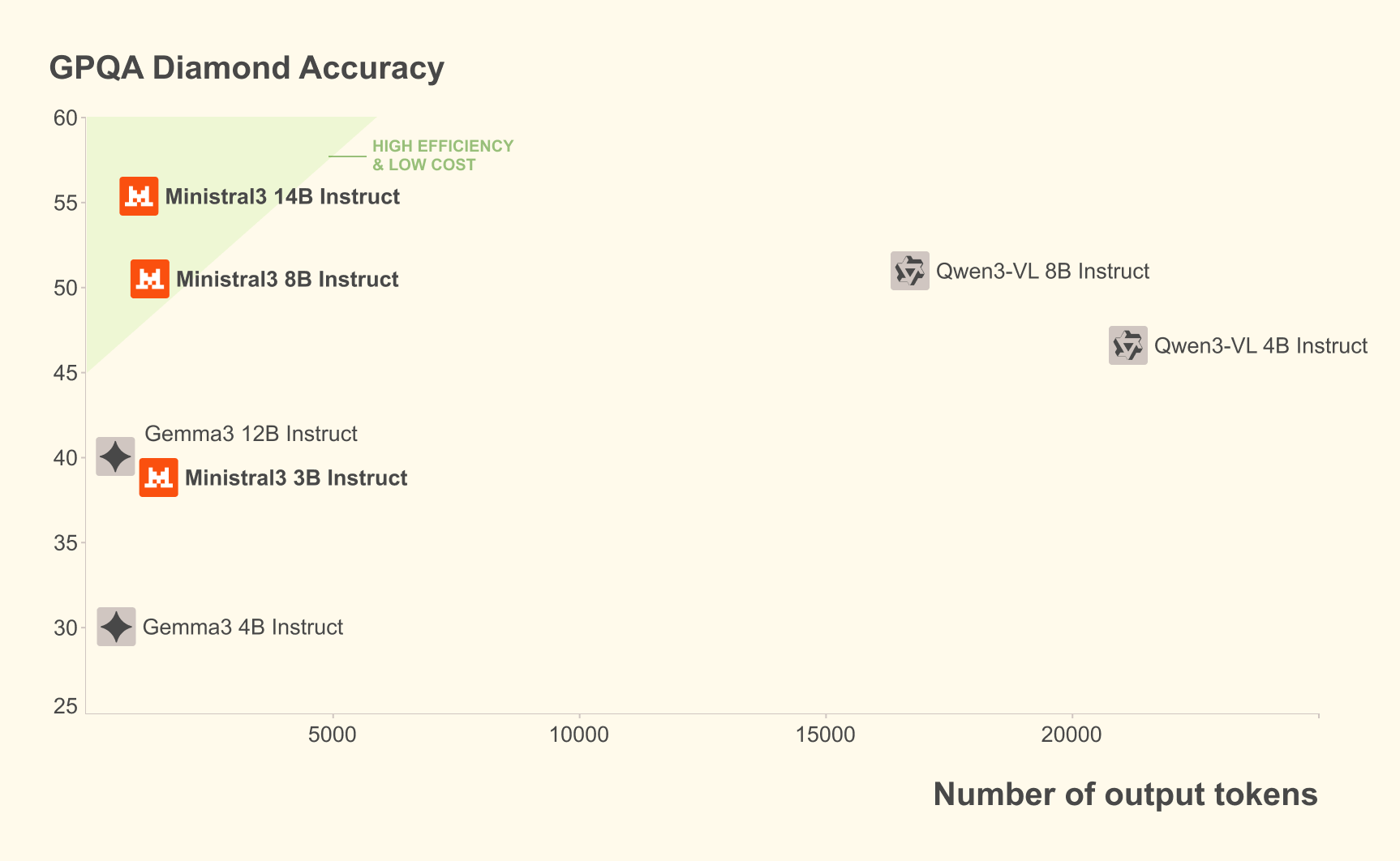
Ministral 3 achieves the best cost-to-performance ratio of any OSS model. In real-world use cases, both the number of generated tokens and model size matter equally. The Ministral instruct models match or exceed the performance of comparable models while often producing an order of magnitude fewer tokens.
Use cases
Ministral 3 Instruct models offer the following capabilities:
- Vision: Enables the model to analyze images and provide insights based on visual content, in addition to text.
- Multilingual: Supports dozens of languages, including English, French, Spanish, German, Italian, Portuguese, Dutch, Chinese, Japanese, Korean, Arabic.
- System Prompt: Maintains strong adherence and support for system prompts.
- Agentic: Offers best-in-class agentic capabilities with native function calling and JSON outputting. Edge-Optimized: Delivers best-in-class performance at a small scale, deployable anywhere.
- Apache 2.0 License: Open-source license allowing usage and modification for both commercial and non-commercial purposes.
- Large Context Window: Supports a 256k context window.
Benchmarks
Ministral 3 Instruct
| Model | Arena Hard | WildBench | MATH Maj@1 | MM MTBench |
|---|---|---|---|---|
| Ministral 3 14B | 0.551 | 68.5 | 0.904 | 8.49 |
| Qwen3 14B (Non-Thinking) | 0.427 | 65.1 | 0.870 | NOT MULTIMODAL |
| Gemma3-12B-Instruct | 0.436 | 63.2 | 0.854 | 6.70 |
| Ministral 3 8B | 0.509 | 66.8 | 0.876 | 8.08 |
| Qwen3-VL-8B-Instruct | 0.528 | 66.3 | 0.946 | 8.00 |
| Ministral 3 3B | 0.305 | 56.8 | 0.830 | 7.83 |
| Qwen3-VL-4B-Instruct | 0.438 | 56.8 | 0.900 | 8.01 |
| Qwen3-VL-2B-Instruct | 0.163 | 42.2 | 0.786 | 6.36 |
| Gemma3-4B-Instruct | 0.318 | 49.1 | 0.759 | 5.23 |
License
Ministral models are available under the Apache-2.0 license.